
Wie die Umsetzung der EU-DSGVO ethische KI-Innovationen und langfristige Wettbewerbsvorteile sichern kann
Mit der zunehmenden Nutzung digitaler Dienste und Technologien erstellen und verarbeiten wir eine Vielzahl personenbezogener Daten, was noch mehr Fragen zum Datenschutz und zur Sicherheit aufwirft. Der springende Punkt ist jedoch: Der Schutz privater Daten ist nicht nur das Richtige, sondern auch ein wesentlicher Bestandteil der Aufrechterhaltung des Vertrauens zwischen Menschen, Unternehmen und Regierungen.
Heutige hochmoderne KI-Systeme verketten automatisch eine Reihe von "Gedanken", die von der KI getätigt werden, um eine Vielzahl von Zielen zu erreichen. AutoGPT ist eines der ersten Beispiele für ein GPT-Modell, das mehr oder weniger selbstständig arbeitet. Da diese Systeme eine riesige Menge an Daten aufnehmen und verarbeiten, können sie möglicherweise Erkenntnisse gewinnen und Türen öffnen, die bisher unmöglich waren.
Wenn "Daten das neue Öl" sind, wie es vor einem halben Jahrzehnt hieß, dann könnten "Mini-AGIs" schon bald eine Zeit einläuten, in der Daten die Lebensgrundlage der digitalen Wirtschaft sind.
Datenschutz by Design
Bei der Entwicklung von KI-Systemen sollten Sie Konzepte des "Privacy by Design" anwenden.
Das bedeutet, dass von Beginn des Entwicklungs-prozesses an über Datensicherheit nachgedacht und sichergestellt wird, dass der Datenschutz in den Entwurf des Systems integriert wird.
Transparenz & Verantwortung
Machen Sie KI-Systeme transparente und nach-vollziehbar. Seien Sie transparent in Bezug auf die Trainingsdaten. Dies trägt dazu bei, Vertrauen bei den Nutzern aufzubauen und zeigt, dass die Datensicherheitsregeln eingehalten werden.
Nutzung lokaler KI-Modelle
Nutzen Sie lokale KI-Modelle innerhalb von Unternehmens-netzwerken. Dies mag zwar den Fortschritt im Vergleich zur Verwendung von APIs großer US-Unternehmen verlangsamen, aber diese Methode hat auch einige klare Vorteile: Sie macht das System zuverlässiger, macht es weniger abhängig von externen Anbietern und sorgt dafür, dass private Daten innerhalb der Unternehmensmauern bleiben.
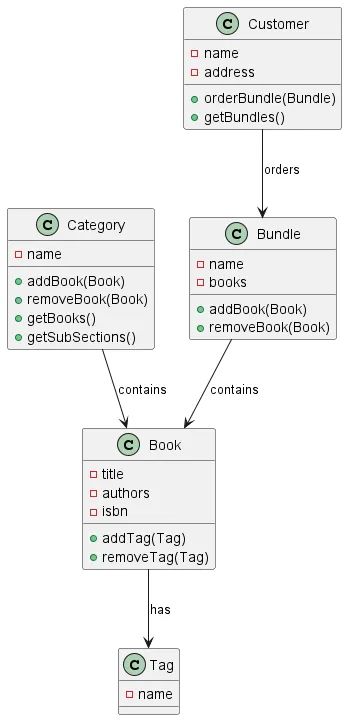
In Minuten aus den Meeting-Notizen zu UML
Schöne neue LLM Welt? (Noch) nicht ganz.
Nach dem Meeting beginnt die eigentliche Arbeit: die Umwandlung aller gesammelten Informationen in etwas Nützliches. Eine der wichtigsten Aufgaben besteht darin, die grundlegenden Diagramme und den Gesamtrahmen zu erstellen, die später im Projekt verwendet werden. Die Erstellung dieser Diagramme kann jedoch eine zeitaufwändige und mühsame Aufgabe sein.
Die Datenschutzbedenken mal außen vor gelassen (denn diese werden sich mittelfristig mit self-hosted LLMs begegnen lassen und die Arbeitsweise ist aktuell noch 'experimenteller Natur'), ist es bereits jetzt möglich mit z.B. Open AI's ChatGPT automatische UML-Diagramme aus Notizen zu erstellen.
Hierbei ist es nützlich, dass OpenAI's Modelle auf dem offenen PlantUML-Dateiformat trainiert sind. Ein einfacher Prompt (d. h. „Befehl“ an das Modell) im Stil von „Erzeuge ein Klassendiagram passend in dem PlantUML-Format aus folgenden Notizen: [...]“ reicht bereits aus.
Alles in allem sollten wir trotz aller noch existierender Probleme einen Schritt zurücktreten und uns ansehen, was hier passiert:
Wir können (theoretisch, wie gesagt, aus Datenschutzgründen noch nicht praxistauglich) die unbearbeiteten Notizen eines Kundenmeetings nehmen und aus diesen ein mindestens 80% nutzbares Klassendiagramm generieren. Das ist schon ein ziemlich großartiger erster Schritt!
© Jörg Amelunxen. All rights reserved.
Wir benötigen Ihre Zustimmung zum Laden der Übersetzungen
Wir nutzen einen Drittanbieter-Service, um den Inhalt der Website zu übersetzen, der möglicherweise Daten über Ihre Aktivitäten sammelt. Bitte überprüfen Sie die Details in der Datenschutzerklärung und akzeptieren Sie den Dienst, um die Übersetzungen zu sehen.